Головний редактор Texty.org Роман Кульчинський: Журналістика даних теж шукає історії
Виділіть її та натисніть Ctrl + Enter —
ми виправимo
Головний редактор Texty.org Роман Кульчинський: Журналістика даних теж шукає історії




Проекти журналістики даних від Texty.org — одні з тих речей, які зсувають українську реальність. Досі не віриться, що вони реалізуються і знаходять підтримку в нашій країні, зважаючи на закони джунг… чи то пак вітчизняного медіаринку. Ми поговорили з головним редактором «Текстів» Романом Кульчинським про те, чому наші ЗМІ так рідко беруться за аналіз великих даних, яким має бути лонгрід, щоби його читали, й коли ми побачимо першу українську візуалізацію даних у VR.
На початку було «дві з половиною людини»
— Для початку, Романе, можливо, у вас є власне визначення журналістики даних? Що це, для кого й навіщо?
— Ми робимо проекти й не надто замислювалися над визначеннями. Якщо узагальнити, — це проекти, які дозволяють зрозуміти, про що свідчать великі масиви даних. Тисячу років тому люди думали, що земля стоїть на трьох китах, проте згодом вони, усвідомивши закони астрономії, зрозуміли: Земля кругла. Так само тепер: люди живуть і не уявляють, що відбувається довкола них насправді. Інформації настільки багато, що людям дуже важко розібратися. Вони роблять судження, базовані на тому, що сказав друг чи знайомий, але це лише одиничні думки. Щоби побачити загальну картину — треба проаналізувати дані. Ми хочемо показати людям реальний світ, у якому вони живуть. І це можна робити завдяки аналізу великих масивів даних. Перевага сучасного світу в тому, що продукується дуже багато даних через телефони, інші електронні пристрої, соціальні мережі. Не кажу вже про ті дані, які збирають урядові структури. Якщо коротко сказати, що таке журналістика даних, — це та ж журналістика, але шукає вона історії, заховані в даних.
— Ви вже шість років очолюєте «Тексти».Розкажіть, що вдалося за цей час зробити,а що ні, що плануєте далі?
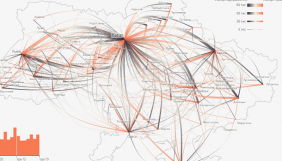
— Ми починали цей проект «удвох із половиною»: я, мій колега Анатолій Бондаренко й новинар, який працював на півставки. У нас не було офісу, всі статті писали фрілансери. До того ж, крім Анатолія, в жанрі журналістики даних працювати ніхто не вмів. Тепер у нас є офіс, команда й цілих чотири людини, які займаються журналістикою даних. Вони постійно працюють над різними проектами. Ми двічі потрапляли до списку фіналістів міжнародного конкурсу з журналістики даних Data Journalism Awards. У 2016 році з проектом «Гроші, метри, два авта» — інтерактивною грою на основі декларацій чиновників. У 2012-му з проектом «Закупівлі». Думаю, це непогані успіхи.
Мені хотілося б, щоби ми мали повноцінну редакцію, в якій працює і служба новин, і декілька репортерів, котрі готували би лонгріди. При цьому жили не на грантові гроші як ми нині, а за рахунок ринку. Але я розумію, що це неможливо в принципі. Навіть в Америці серйозна журналістика не є окупною. Вона живе на дотації, на пожертви, на гранти. Виходячи з цих реалій, ми плануємо скромне розширення: будемо шукати одного дизайнера й одного журналіста. Є задумки, як частково комерціалізувати контент. Але мрія залишається мрією: зробити редакцію мінімум утричі більшою, і щоби велика частина займалася журналістикою даних і така ж частина опікувалася традиційною журналістикою.

— Ви почали займатися «Текстами», після того, як пішлиз «Українського тижня»…
— Із «Тижня» ми пішли на початку 2009-го. Потім створили проект ZA.UA, знайшли інвестора. Рік попрацювали, поки в інвестора не закінчилися гроші. На базі цього сайту й утворилися «Тексти».
— Знаходив інформацію, що саме у 2010 році на конференціїв Амстердаміпоняття «журналістики даних» і сформувалося.
— Я не історик. Знаю, що одним із перших розвивати журналістику даних почав американець українського походження Адріан Головатий раніше 2010-го — у 2004-му (детальніше про історію журналістики даних читайтетут. — В. М.). Він створив першу інтерактивну мапу злочинності Чикаго. Потім галузь почала розвиватися.
— І все ж: шість років тому, Україна. Чому ви вирішили займатися саме цим напрямом, зважаючи на специфіку нашої країни й медіаринку?
— Усе дуже просто. У нас був сайт і бачення, як його розвивати. Ми хотіли робити медіа, яке спеціалізується на якісних текстах, лонгрідах. Але це нікому не було цікаво. Дуже важко зрозуміти, що таке «якісний текст», а що «неякісний», що таке «хороша журналістика», а що «погана». «Написано, отже журналістика». Тим часом у Анатолія, співзасновника сайту, бекґраунд програмістський, і він знав інструментарій для аналізу даних, який саме в той час почав активно розвиватися. Ми зробили декілька «пробних» проектів. Перший — рейтинг вишів на основі ЗНО абітурієнтів. Там не було інфографіки, але був пошук і аналіз даних. Такий проект зацікавив багатьох, особливо донорів, які готові були це фінансувати. Так ми зрозуміли, що ринок цікавлять не тексти, а робота з даними. Адже тексти розпливчасті, як би ти їх не структурував. Текст — це не цифра, його можна трактувати по-різному.
— У своїй роботіви використовуєте безкоштовні сервіси з візуалізації?
— Ні. Всі наші проекти журналістики даних — це програмування. Інструменти використовуються для кожного набору даних різні. Приміром, якщо працюємо з картами, то, як правило, використовуємо OpenStreetMaps. Постійно використовуємо мови програмування R, Python, бібліотеку d3. Крім того, регулярно з'являються якісь нові інструменти.
— Як гадаєте, чому матеріали в форматі журналістики даних майже не з'являються в українських ЗМІ?
— Чому ж, з'являються. «Українська правда» намагається працювати в цьому напрямі, і в них непогано виходить, KyivPost, деякі громадські організації... Найбільша проблема в тому, що це працемісткий процес, тобто редакції потрібно знайти людину, яка поєднує в собі трьох: журналіста, програміста й дизайнера. Можна набрати цілу команду, але тоді процес ускладнюється й дорожчає. Також важче звести докупи зібраний матеріал. Гадаю, це одна з основних проблем, чому досі така журналістика не набула масовості. Хоча, мені здається, великі редакції могли би собі це дозволити, тому що це окуповується. Такі проекти, по-перше, гарно відвідують і завжди потім добирають перегляди. Новини, умовно кажучи, живуть декілька годин чи днів, стаття — тиждень чи місяць, а матеріал із журналістикою даних може жити роками.

— Скільки у вас заходів на подібні матеріали?
— Щоразу по-різному: іноді вистрілює, іноді ні. Перша гра про декларації зібрала 20 тис. переглядів за кілька днів і потім добирала далі. А згаданий матеріал про рейтинг вишів протягом кількох років двічі на рік потрапляв до найбільш читаних статей. Це в момент, коли батьки чи абітурієнти шукали собі якийсь навчальний заклад.
Як приручити невдячні лонгріди
— Редактор Focus.UA Михайло Крігельказав, що формат лонгріду є вкрай невдячним: витрачається багато ресурсів,а переглядів вони набирають якновини. Журналістика даних — більш вдячне поприще?
— Я з Михайлом не зовсім погоджуюся. Ми робили лонгрід про бурштин, його за тиждень прочитало 10 тис. користувачів. Зрозуміло, що новину теж може прочитати така кількість людей, але для нас це рідкість. Так, мабуть, за ті гроші, які ми витратили на цей лонгрід, можна було сто, тисячу новин «наклепати» й набрати більше трафіку. Але якщо лонгрід добре написаний, його будуть читати. Іноді ж «довгі тексти» пишуть украй неякісно. Нещодавно я намагався читати такий матеріал про «Правий сектор», так автор почав описувати його історію, яку й так усі знають. Я той текст так і не дочитав, тому що він нудний. Тобто перегляди — це часто питання якості матеріалу, на мою думку. Хороший лонгрід — це добре зібрана інформація, гарно подана, це майже література, а не реферат. Не треба там мову законопроекту. Тож коли текст гарно написаний і цікава інформація — його будуть читати. Але так, підготовка дорога.
— Раніше ви розповідали, що «Текстам»замовляють створення візуалізацій. Ця практика триває?
— Коли нас було «дві з половиною людини», то до 50 % бюджету складало замовлення на інфографіку. Тепер у цьому відпала потреба. Тому що коштує це не дуже-то й дорого, й це не був аналіз даних. Нам клієнт приносив свої дані, а ми їх візуалізували. Тепер можемо це зробити тільки якщо дуже просять. Адже це забирає час, але не приносить прибутку, за який можна утримувати частину редакції. Втім, ми цей напрямок залишаємо: якщо гранти раптом закінчиться, ми змушені будемо радикально скоротити штат і, мабуть, відновити візуалізації на замовлення, щоби «триматися на плаву».
— А як щодо Школи візуалізації даних, яку ви започаткували? Вона діє чи вже ні?
— Започатковуючи школу, мали дві цілі: хотіли знайти собі потенційних співробітників, а також нам потрібні були кошти на утримання сайту. Але ми стикнулися з такою проблемою: скільки ми люди не навчаємо, фідбеку дуже мало. Насправді дуже мало людей продовжували займатися аналізом даних після наших семінарів. Люди прийшли, послухали — як лекцію, бо цікаво й модна назва. Це один момент. А другий — те, що нас почали часто запрошувати читати семінари, лекції, це був просто якийсь вал, і ми не справлялися з усім. Тепер не приймаємо всі такі запрошення, тому що підготовка лекції займає дуже багато часу, і в мене особисто — дуже багато енергії. Краще цей час витратити на якийсь матеріал.
Із чого почати проект аналізу даних і скільки він може тривати
— Розкажіть, будь ласка, як відбувається створення таких матеріалів.Наприклад, я хочу зробити проект, аналогічний до вашого «Громадяни пасажири», але в менших масштабах: щоденні міграції людей у Києві й наскільки відповідає їм транспортна система. Ізчого мені починати,якими сервісами користуватися? Чи можу я зробити це сам, чи потрібна команда? Скільки часу в мене це займе?
— Щодо інструментів для вас — є відкритий перелік у Google-таблиці. До кожного завдання потрібно підбирати свої інструменти. Як це відбувається в нас? Якщо ми хочемо проаналізувати міський трафік Києва, то спочатку дивимося, які є дані. Які їздять маршрутки, чи є цей трафік, яка наповненість цих маршруток. Перевіряємо автобуси, тролейбуси, як їздить метро, чи є трафік по ньому: скільки людей заходить, скільки виходить. Чи є трафік автомобільний, чи він зафіксований, чи є він у відкритому доступі? Здається, його немає. Прекрасно, немає даних — немає матеріалу…
— :)
— Якщо вас це все ж не влаштовує, варто спробувати дістати ці дані.
— Скільки часу це може тривати з нашими державними структурами?
— Щоразу по-різному. Живий приклад — наша карта закинутих будинків. Щоби зібрати дані про них, треба було по декілька разів писати запити в усі районні адміністрації Києва. Цим займалася наша практикантка. Власне, на збір даних вона витратила більше двох місяців. Сам проект тривав більше ніж півроку. Хоча практикантка це робила не постійно, а коли був час. Деякий час пішов на те, щоби розібратися, кому саме в райадміністрації писати запити. На нашу першу хвилю запитів прийшли відповіді у стилі «а ми цим не займаємося». Розібралися, послали запити їм. Відповіді прийшли на папері, їх потрібно було перенести в електронний формат.
В іншому проекті ми досліджували, чи є ліцензії на торгівлю алкоголем у магазинів. ДФС виклала всі дані у відкритий доступ, але вони були дуже неповні. Для уточнення ми писали запити, нам відповіли приблизно як по закону, — за п'ять днів. Може, часом трохи довше. Але повних даних у державних структур може й не бути.
Інша історія — українська залізниця. На хвилі реформ Олексій Соболєв, радник міністра інфраструктури Андрія Пивоварського, вийшов із нами на контакт і сказав: відомство готове проводити реформи, зацікавлене у відкритості й хоче привернути увагу до даних, які є в міністерства. Так народився спільний проект. Тобто вони надали дані, а ми їх проаналізували й візуалізували. Ми з ними поговорили, й вони показали дев’ять наборів даних, які в них були. Ми вирішили сконцентруватися на даних по пасажиропотоку, тобто пасажирському трафіку «Укрзалізниці». На нашу думку, це було найцікавіше. Отримували дані ми місяці два.
Щоразу з державними даними по-різному. Ще за режиму Януковича ми написали запит у київське ДАІ, щоб вони вислали нам усі точки ДТП із зазначеними часом, адресами, кількістю автомобілів, їхніми марками, кількістю постраждалих. І вони надали нам їх за п’ять днів.
— Гаразд, уявімо, дані я зібрав, який наступний крок?
— Треба чистити дані. Візуалізації створюються за допомогою програм, а для них важливими є стандартно заповнені всі поля. Наприклад, якщо стоїть «1.1», то щоб усюди стояла крапка, а не кома. У нашому проекті про рейтинг шкіл на основі результатів ЗНО випускників були назви шкіл, але не було адрес, а ми хотіли прив'язати школи до карти. Ми знайшли список шкіл на сайті ЦВК, бо всі дільниці зазвичай у школах. Отже, у нас було дві бази, які треба було звести, але не виходило. Тому що в першій базі було написано СЗШ, а в базі з адресами — середня школа. Саме чистка даних забирає багато часу.
Після того, як ви почистили інформацію, починаєте її аналізувати. Жоден аналіз бази нецікавий, цікаво зіставити її з чимось іншим, показати якусь тенденцію. Коли ми це цікаве «намацали», пробуємо показати візуально.
Далі потрібно зрозуміти, що ці дані показують, що там є цікавого… Можливо, нічого й не буде. Приміром, коли Міносвіти минулого року оприлюднило дані про ЗНО, ми зробили аналіз. Що там було цікаво: як здають діти в селі тестування, як у місті; як здають хлопці, як дівчата — це основні теми. Але ми хотіли «копнути» далі, подивитись, як здають по регіонах, чи є якісь відмінності. Зрештою, ми гралися з цим набором даних два тижні, але так цікавої історії й не знайшли. Розфарбувати карти, показати кольором, хто як здає, зробити «аби зробити» — це не для нас. Треба знайти цікаву історію, щоби читач сказав: «Вау! Це так просто, а я цього не знав!». Якщо така історія є, тоді ми починаємо працювати й дивитися, який інструментарій можна застосувати.
— Скільки часу йде на візуальну частину?
— Відсотків 20 роботи з усього процесу. Найбільша проблема — це все ж робота з даними: почистити і зрозуміти, що всередині них є… Але в нас усі проекти тривалі.
— І скільки, приміром, часу у вас зайняла підготовка проекту «Тролесфера»?
— Малювали ми її місяць-півтора. Збирала дані практикантка місяців шість, вона працювала 12 годин на тиждень. Але вона дуже скрупульозно їх збирала вручну, потім дозбирувала, виводила статистику.
Візуалізація даних у VR: хто її буде дивитися
— Який би підручник ви порадили для тих, хто цікавиться журналістикою даних?
— Є підручник, який так і називається «Журналістика даних: Посібник». Ми ж його й переклали з англійської (він тут. — В.М.).
— Є тенденції до візуалізації даних у віртуальній реальності. Вам уже траплялося таке?
— Так, і навіть більше — ми хотіли зробити такий проект. У нас у штаті є талановита й дуже працьовита Ярина Михайлишин. Вона колись прийшла на семінар із інфографіки, який організував MediaNext, ми там викладали. З усього потоку вона єдина продовжила вчитися створювати інфографіку, працюючи з нами як волонтер, пізніше — як фрілансер. Згодом Анатолій почав її вчити програмування, і за певний час вона стала невід’ємною частиною нашої команди.
Півтора роки тому Ярина поїхала до США за програмою Фулбрайта, де вибрала собі спеціальність «журналістика даних». Там вона досить добре навчилася програмувати, стажувалася у The New York Times. Вона й далі наша співробітниця. Наш проект «Пролітаючи над Драгобратом» обговорювався як проект у віртуальній реальності. Але для того, щоб він був у VR, треба, щоби хтось його дивився, щоби люди мали відповідні окуляри. Коли The New York Times робить такі проекти — воно розсилає окуляри своїм підписникам. 5 доларів для такого видання не гроші. Крім того, вони знають, на які адреси такі окуляри надсилати. Якби ми зробили такий проект в Україні, хто його подивився, на чому? Карпати ми можемо переробити у VR, але ринок, на жаль, не готовий.
— Якщо підбивати підсумки 2016 року, який проект є найбільш знаковим для вас?
— Про Карпати вийшло дуже ефектно й красиво, але знаковою я все ж вважаю «Тролесферу». Він викликав і найбільший резонанс, і робота, яку ми провели зі збирання даних, вражає.